話題の「Talk to the City」をチーム安野さんのソースコードで試してみた!

ブロードリスニングのためのツール「Talk to the City」
「Talk to the City(TTTC)」は、ブロードリスニング(広範囲の意見を収集・分析する手法)を目的としたツールです。2024年の衆議院選挙で日本テレビの選挙報道の際に、チーム安野さんがアップデートを行い、そのソースコードが公開されています。
GitHubリポジトリ:https://github.com/ntv-experiment-public/shugiinsenyo2024-tttc
また、安野たかひろ事務所のnoteでも紹介されています。
【地上波世界初】都知事選で使ったブロードリスニングの技術で衆院選を解析してみた
このツールは、市民の声を可視化し、社会的な課題を浮かび上がらせることを目的としています。特に選挙期間中において、有権者の関心や意見のトレンドを分析するために活用されました。
ソースコードをダウンロードして調整
今回、GitHubで公開されたTTTCのソースコードをダウンロードし、実際にテストを行いました。
衆院選(2024年10月)から少し時間が経っているせいか、そのままでは動かなかったので少し時間がかかりました。部分的にオリジナルのソースに切り替えたり、コメントアウトしたので全く同じではありません。また、動くように設定する方法は環境により異なると思います。
[広告:システム開発のご相談はCoolwareへ]
ソースコードをサーバーに置く
ソースコードをサーバー上に置いてください。サーバーの設定などは割愛します。
以下はtalk-to-the-cityのファイル構造です。turboとscatterがありますが、scatterの方を使います。
「pipeline」というフォルダの中に入力データや環境設定ファイル、プロンプト(AIへの指示文)などが入っています。
集めた意見をCSVファイルにする
csvファイルは決められた形式に整えてください。UTF-8にしないと動きませんでした。
csvファイルを取り込む
scatter/pipeline/inputs の中に、整えた csvファイル を置きます
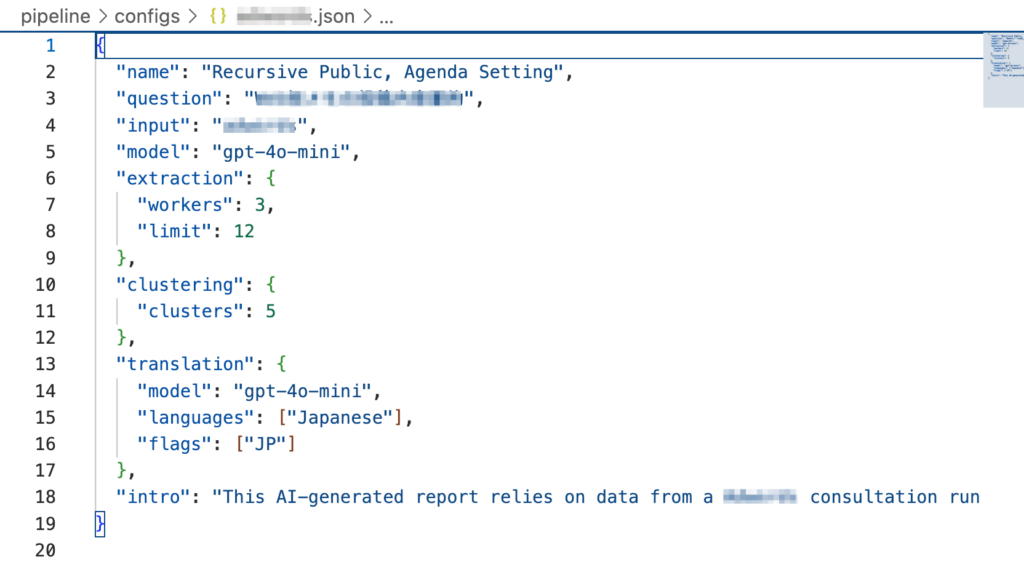
設定ファイル(json)を置く
scatter/pipeline/configs の中に、csvファイルに対応するjsonファイルを置きます。configsフォルダに既に入っているjsonファイルをコピーして、読み込むCSVファイル名などを書き換えて作ると良いと思います。
AIと接続
scatter ディレクトリに移動
cd /var/www/html/talk-to-the-city-reports/scatter/source venv/bin/activateAIと接続
export OPENAI_API_KEY=ここにキーを書く解析を実行
pipelineディレクトリに移動して先ほどのjsonファイルを実行
cd pipeline
python main.py configs/example-polis.json- 以前の実行結果がある場合は、scatter/pipeline/outputs 内にある出力結果のフォルダを消してから再実行してください。
- プロンプトや入力データを変更したら再実行してください。
プロンプトの調整
思ったような分析結果が出ない場合は、scatter/pipeline/prompts 内のプロンプトをいろいろ調整して試してみると良いと思います。
ブラウザ上で解析結果を確認する
お使いのサーバーの以下のディレクトリにアクセス
/pipeline/outputs/ディレクトリ名/report/SHARE info で作ったナレッジメモサイト「Web担メモ」の投稿内容を解析したところ以下のように散布図が表示されました。

もとのTalk to the Cityに比べると、お気に入り機能がついていたり、機能が増えています。
たくさんの意見を集めるには
Talk to the Cityを使うには、前提として大量の意見を集める必要があります。
チーム安野さんは、X(旧Twitter)上の意見を収集していましたが、意見収集用のサイトを別に開設する方法もあります。
投稿型サイト作成サービスSHARE info Bizなら、ユーザーが意見を投稿できるサイトをスムーズに開設できます。作ったサイトのURLをホームページに載せたりQRコードを配ったりして周知し、そこから意見を募るということができます。
集まった意見は管理画面の「エクスポート」からcsvファイルとして出力できます。出力したファイルのままではtalk to the cityに取り込むことができないので、不要な行を削ったり、定型に沿ったヘッダーをつけたりして整えます。
例えば自治体などで使う場合は、SHARE info を使って意見収集用の特設サイトをすばやく作るのもよいでしょう。
ユーザー投稿型サイトを運営しよう
投稿を要約してくれるAIチャット付き
「Q&Aサイト」「コミュニティサイト」「意見募集サイト」が
簡単に運営できるクラウドサービス
AIがサイトの内容を情報源に質問に回答
SNSでフォローする

SHAER info AI
